Model Execution Workflow
The Model Execution Workflow on the Gesund.ai Platform is built to handle prediction tasks seamlessly — from individual image inference to large-scale batch predictions and the recovery of failed jobs. This ensures a reliable and efficient AI deployment experience for all users.
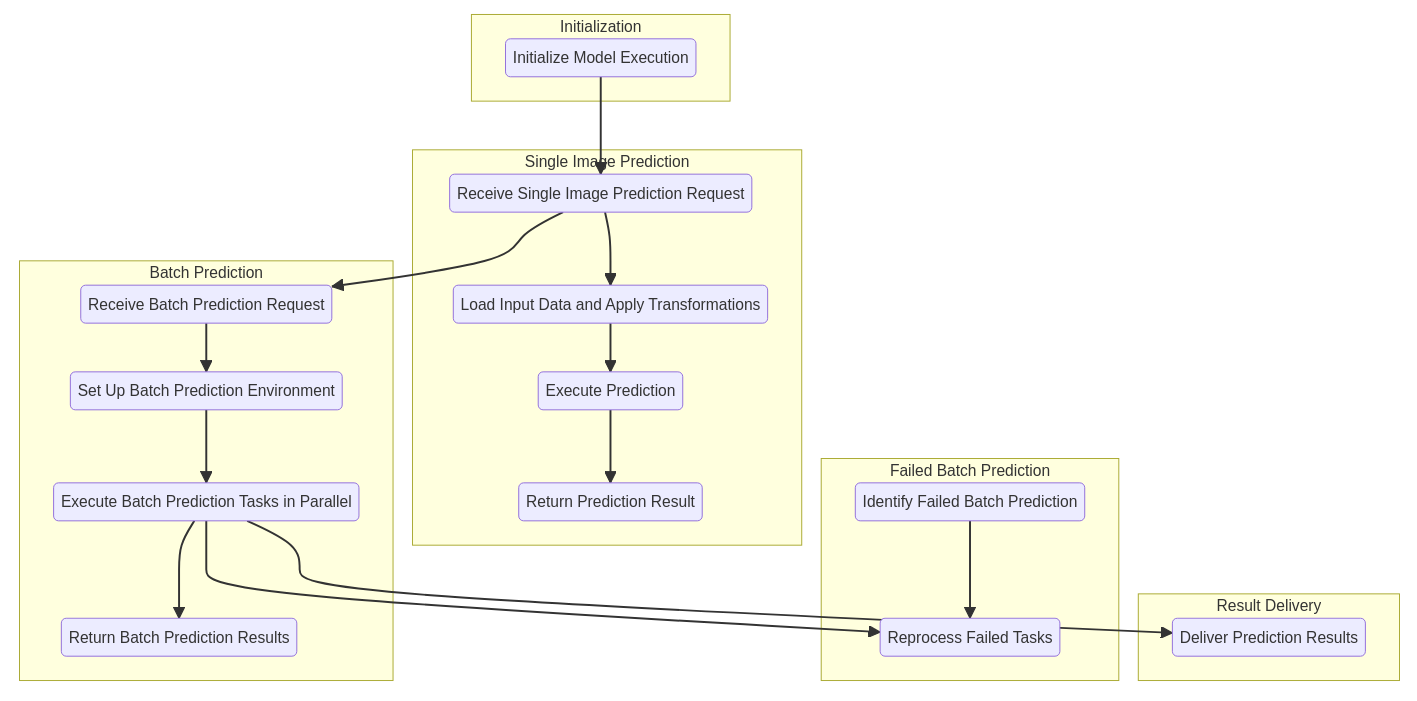
1. Initialization
- The platform initializes necessary components and system resources.
- This includes model loading, environment setup, and configuration validation for prediction readiness.
2. Single Image Prediction
When a single image prediction is requested:
- Request Handling: The system receives the request and extracts image and dataset IDs.
- Preprocessing: Input data is loaded and any user-defined transformations are applied.
- Inference: The selected model processes the image to generate predictions.
- Response: Results are returned to the user promptly.
3. Batch Prediction
For multiple image predictions:
- Batch Intake: The system registers and queues multiple prediction jobs.
- Environment Scaling: Workers are dynamically provisioned to match workload demands.
- Parallel Processing: Predictions run concurrently for optimal performance.
- Result Aggregation: Results from all tasks are combined and returned collectively.
4. Failed Batch Recovery
If any tasks fail during batch execution:
- Failure Detection: The platform identifies and logs failed tasks automatically.
- Retry Mechanism: Failed jobs are retried after addressing system or data-related issues.
- Completion Assurance: Ensures a high success rate by recovering from transient errors.
5. Result Delivery
- Live Updates: Users receive real-time feedback on prediction progress.
- Output Access: Successful results are made accessible through the interface.
- Error Reporting: When issues occur, detailed error logs help users troubleshoot quickly.
This robust execution pipeline ensures that model inference — whether for a single case or at scale — remains efficient, resilient, and transparent for all users.